Decision Transformer for Robot Imitation Learning
Abstract
Traditional reinforcement learning relies on policy optimization to maximize cumulative reward. This project reframes RL as a sequence modeling problem, using the Transformer architecture instead of dynamic programming or policy gradients. We extend the original Decision Transformer by incorporating mixed-quality input data (machine-generated, multi-human, and proficient-human demonstrations) using the robomimic dataset. By introducing a semi-sparse reward function, this approach quantifies the benefit of return-conditioned imitation learning, outperforming standard behavioral cloning on mixed-quality datasets—particularly in the Lift and Can robotic manipulation tasks.
📄 View on Mobile
For the best experience on mobile, download the PDF or open it in your browser's PDF viewer.
Mixed-Quality Data
Handles datasets combining machine-generated, multi-human, and expert demonstrations—realistic for production robotics
Semi-Sparse Rewards
Novel reward shaping that encourages faster task completion and provides stronger learning signal
Strong Performance
94% success on Lift task, 81% on Can task—significantly outperforming behavioral cloning baselines
Motivation & Background
Real-world imitation learning often struggles with datasets of varying quality. Traditional RL approaches require carefully curated demonstrations, but in practice, we often have mixed-quality data from different sources: expert demonstrations, sub-optimal human trajectories, and machine-generated data.
Reinforcement Learning Framework
At each timestep t, an agent perceives a state st and selects an actionat, leading to a reward rt. The policy maps states to actions:
The return-to-go (RTG) at timestep t is the sum of future rewards:
Decision Transformer uses RTG values to differentiate between low and high-quality demonstrations.
Why Transformers?
- Sample efficiency: Fewer samples needed for high performance
- Stable training: Large-scale training without policy gradient instability
- Sequence modeling: Natural fit for temporal decision-making problems
- Proven track record: Success in NLP and vision transfers to RL domains
- Parallel computation: GPU-friendly architecture unlike RNNs
Return-Conditioned Behavioral Cloning
By adding RTG as an input, we can condition the policy on desired performance:
Low-quality data helps increase training set size while we can replicate only high-quality actions at test-time by specifying an expert-level target return.
Goal: Quantify the benefit of return-conditioned imitation learning on mixed-quality data by reinterpreting RL as sequence prediction—eliminating the need for value function estimation or policy gradients.
Architecture
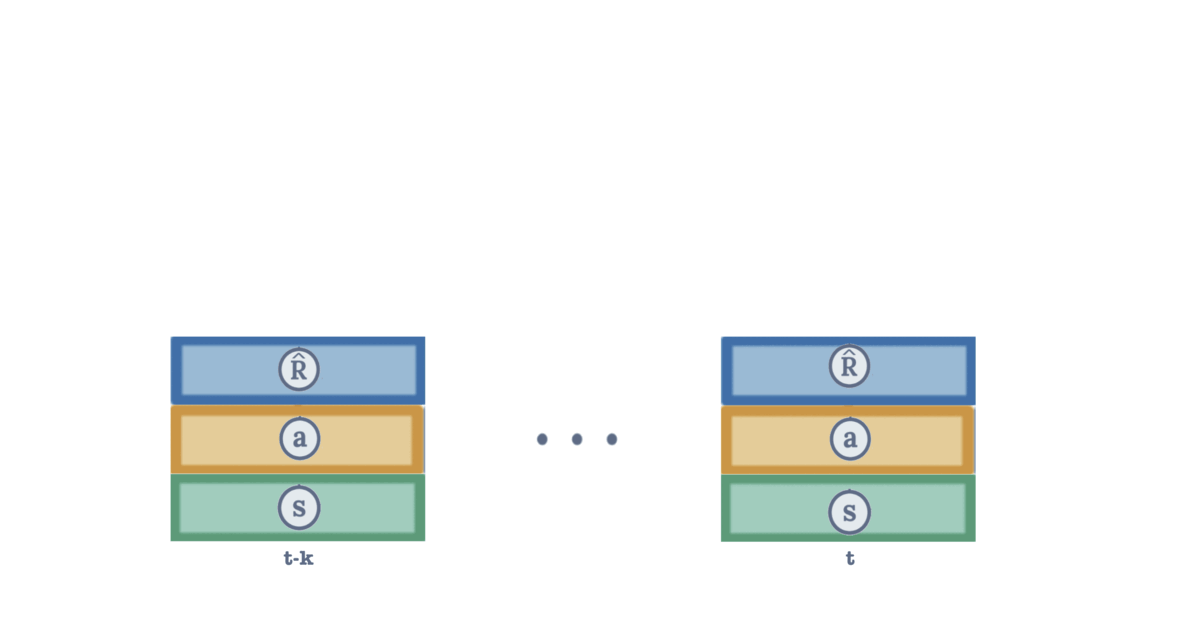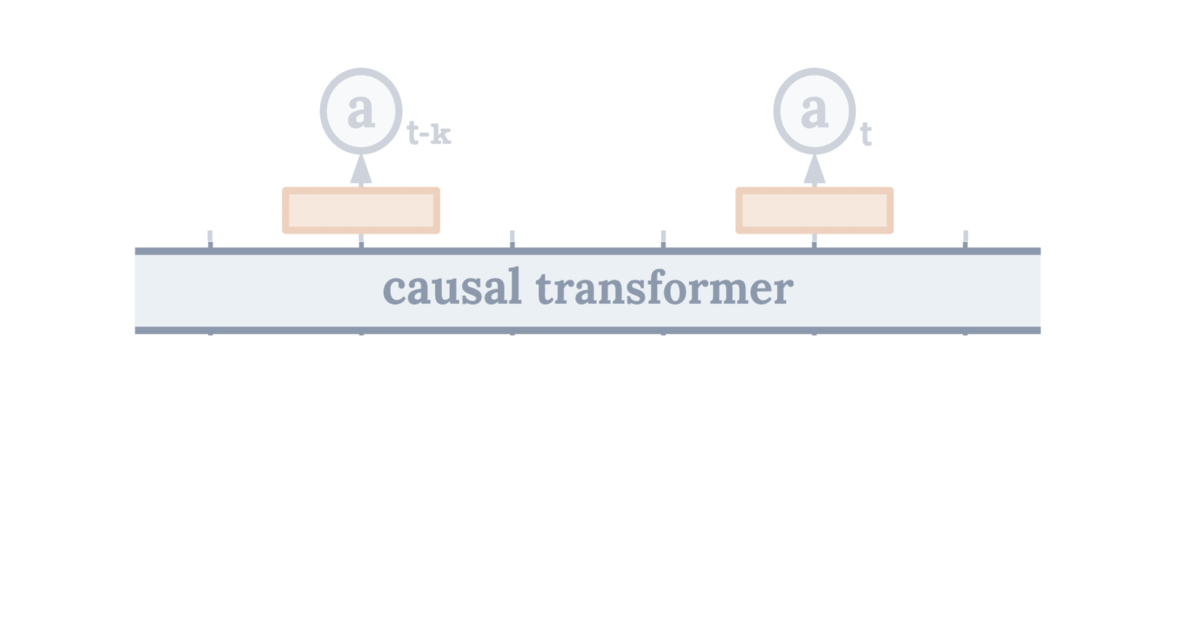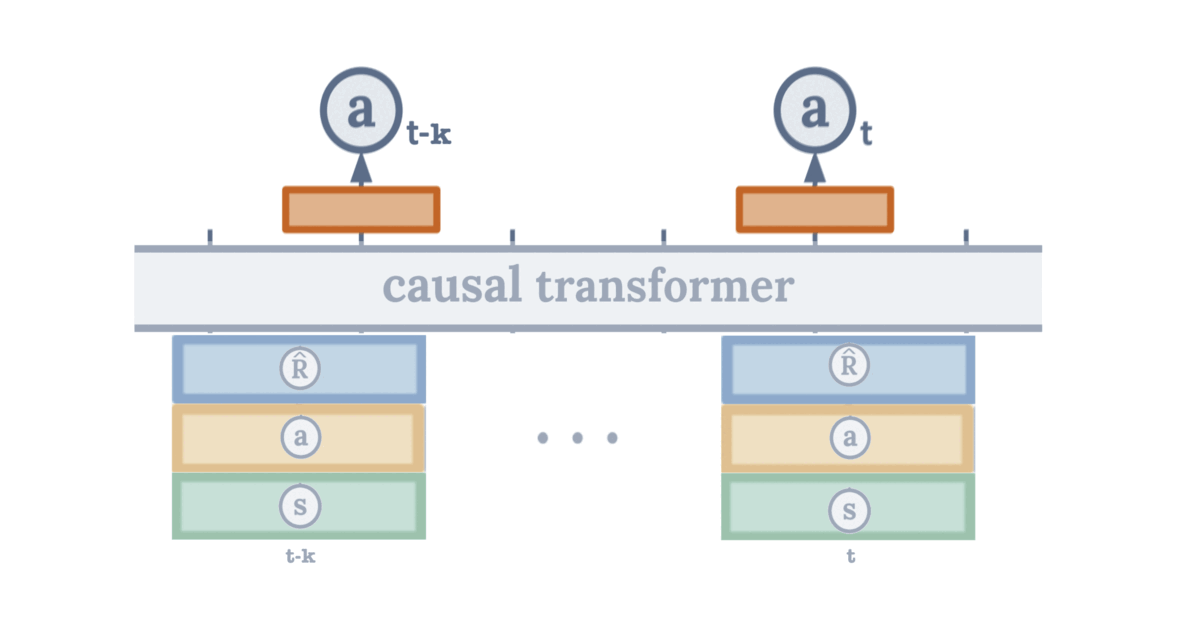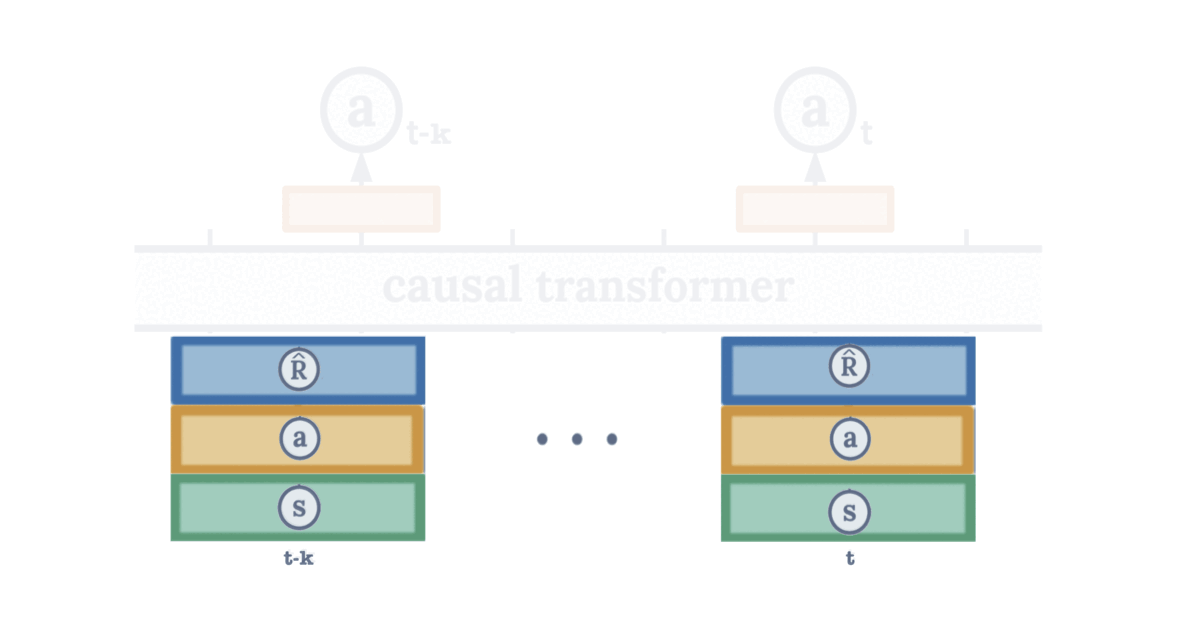
Architecture diagram showing how states, actions, and return-to-go tokens flow through the transformer
We input states, actions, and returns-to-go into a causal transformer to predict desired actions. A key innovation: we combine states, actions, and return-to-go into one tokenper timestep. This shortens the sequence length and reduces computational requirements compared to the original Decision Transformer.
Key Architectural Differences
- Token compression: Concatenate (st, at-1, R̂t) → single token
- Stochastic policy: Multi-modal GMM instead of deterministic actions
- Pre-Norm architecture: Normalization before attention/FF layers for training stability
- Learned positional embeddings: Better temporal modeling than fixed sinusoidal
Implementation Details
The TransformerEncoder processes the concatenated input sequence through multiple layers of self-attention:
# From transformer.py
def forward(self, states, pad_mask):
batch, length, dim = states.shape
# Causal masking prevents looking at future tokens
mask = self.make_attn_mask(x=states, pad_mask=pad_mask)
# Add positional embeddings
pos_emb = self.position_embedding(pos_idxs)
traj_emb = self.ff1_state(states) + pos_emb
# Self-attention layers
for layer in self.layers:
traj_emb, attn = layer(self_seq=traj_emb, self_mask=mask)
return self.norm(traj_emb)Method
1. Data & Tasks
Focused on Lift (cube lifting) and Can (placing can in bin) tasks from the robomimic benchmark. Combined all dataset types into an "All" category to test robustness:
MG (Machine-Generated)
Mixture of suboptimal data from state-of-the-art RL agents. Heavily weighted in "All" dataset.
PH (Proficient-Human)
200 high-quality demonstrations from expert teleoperators.
MH (Multi-Human)
300 demonstrations from teleoperators of varying proficiency.
2. Semi-Sparse Reward Function
The Problem: Robomimic uses sparse binary rewards (1 for success, 0 otherwise). We attempted to enable dense rewards, but found the dense reward was uncorrelated with dataset quality. For example, in the Lift dataset, "proficient human" (PH) had the lowest return while "machine generated" (MG) had the highest—due to sequence length mattering more than success rate.
Our Solution
Manual reward shaping with a success bonus that decreases every timestep:
If success happens at timestep 100, reward bonus = 400. At timestep 499, bonus = 1. Past 500 steps, bonus = 0.
# From data_utils.py - RTGSequenceDataset.get_item()
# Find timestep that leads to success
for t, d in enumerate(future_info["dones"]):
if d:
break
success_step = index_in_demo + t + 1
# Apply semi-sparse reward function
future_rews = future_info["rewards"].copy()
future_rews[t] = max(500.0 - success_step, 0.0)
future_rews[t + 1:] = 0.0
# Compute return-to-go via reverse cumsum
rtgs = np.flip(np.cumsum(np.flip(future_rews)))- Encourages efficiency: Faster completions get higher returns
- Reduces bias: Long, meandering trajectories no longer dominate
- Wider RTG distribution: Better signal for return-conditioning
- Maintains sparsity: Still depends on task success, not per-step progress
3. Policy Architecture: Gaussian Mixture Models
Unlike the original Decision Transformer's deterministic policy, we train a multi-modal stochastic policyusing Gaussian Mixture Models. This is crucial for modeling the multi-modal action distributions present in human demonstrations.
# From agent.py - GMM policy head
def make_action_dist(self, params):
if self.policy == "gmm":
# Split params into means, log_stds, and mixture weights
idx = self.gmm_modes * self.d_action
means = rearrange(params[:, :, :idx],
'b l (m p) -> b l m p', m=self.gmm_modes)
log_std = rearrange(params[:, :, idx:2*idx],
'b l (m p) -> b l m p', m=self.gmm_modes)
logits = params[:, :, 2*idx:]
# Create mixture distribution
comp = pyd.Independent(pyd.Normal(loc=means, scale=std), 1)
mix = pyd.Categorical(logits=logits)
dist = pyd.MixtureSameFamily(mix, comp)
dist = TanhWrappedDistribution(base_dist=dist, scale=1.0)
return distConfiguration
- • 512-d embeddings
- • 2048-d feedforward
- • 4 transformer layers
- • Context lengths: 1, 3, 10, 20
- • 5 GMM modes (default)
Why GMM?
- • Captures multi-modal action distributions
- • Models multiple valid strategies
- • Outperforms Gaussian on Can task
- • Better for varied human demonstrations
4. Training Objective
Decision Transformer uses a standard sequence modeling objective, greatly simplifying implementation relative to offline RL techniques. We optimize network parameters θ to maximize the probability of true actions given the context:
Sequence Modeling Objective
Define context token as concatenation of state, previous action, and RTG:
Optimize to maximize log-likelihood of actions conditioned on k previous context tokens:
This is equivalent to supervised learning on the action labels, treating trajectory data as sequences.
# From learn.py - Loss computation
def compute_loss(self, batch):
state_seq = batch["seq"].to(DEVICE)
actions = batch["actions"].to(DEVICE)
pad_mask = batch["pad_mask"].to(DEVICE)
# Forward pass through transformer
action_dist = self.agent(state_seq, pad_mask=pad_mask)
# Compute negative log-likelihood
logp_a = action_dist.log_prob(actions)
valid_mask = (~pad_mask).float()
loss = (-logp_a * valid_mask).sum() / valid_mask.sum()
return lossOptimization
- • AdamW optimizer for stable training
- • Linear warmup: 2000 steps
- • Batch size: 256 sequences
- • Training time: ~6 hours on RTX 3090
- • Gradient clipping: Max norm 5.0
Evaluation
- • 8 parallel environments for efficiency
- • Success rate as primary metric
- • Target RTG: 95th percentile of training data
- • Rollout length: Max 200 timesteps
Results
Lift Task (All Dataset)
| Model | Success Rate | Notes |
|---|---|---|
| Naive BC | 35% | Fails on mixed-quality data |
| DT-3 | ~75% | Strong improvement with return conditioning |
| DT-20 | 94% | Best performance—filters noise effectively |
Can Task (All Dataset)
| Model | Success Rate | Notes |
|---|---|---|
| Naive BC | 14% | Struggles with multimodality |
| DT-3 | 81% | Outperforms all baselines |
Key Findings
- Longer context sequences (k=10-20) improve action prediction and robustness
- GMM policies outperform Gaussian on multi-modal demonstrations
- Larger Transformers show better performance than smaller architectures
- Return-conditioning helps filter low-quality data during training
Key Findings & Challenges
Challenge: Action & RTG Conditioning Can Harm Performance
At test-time, DT conditions on its own slightly inaccurate actions and RTG values. These inaccuracies can compound over trajectory length, potentially causing lower success rates than BC baselines.
- Distributional shift: Training data contains perfect actions, but test-time uses imperfect predictions
- Error compounding: Small mistakes early in trajectory affect later predictions
- Mitigation: Larger models are more robust to input variations
Finding: Longer Context Improves Training Fit
Despite equal model sizes and hyperparameters, training loss improves with longer context sequences. Context lengths of k=20 significantly outperform k=3 on mixed-quality data.
- Resolves ambiguity: Longer history clarifies which demonstrator is being imitated
- Multi-modal handling: Better differentiation between human strategies
- Trade-off: Diminishing returns beyond k=20 for these tasks
Finding: Model Size Matters for Mixed-Quality Data
Larger Transformers (512-d embeddings, 2048-d FF) outperform smaller ones (200-d, 800-d FF) across all context lengths on Can-All task:
- DT-3 (Large): 81% success vs 65% (Small)
- Generalization: Large networks benefit from diverse mixed-quality data
- Contrast with pure imitation: Small models preferred when only expert data available to prevent overfitting
Finding: Return-Conditioning Enables Quality Control
DT can replicate a range of performance qualities by varying the target return at test-time. As target RTG increases, so does actual return and success rate.
- Flexible deployment: Single model serves multiple quality levels
- 95th percentile heuristic: Replicates high-quality behavior while staying in-distribution
- Limitation: Struggles to replicate very low returns (slow solutions) due to limited context
Discussion & Future Work
This work demonstrates that Decision Transformers can successfully learn from mixed-quality robotic demonstration data, significantly outperforming behavioral cloning when demonstrations come from multiple sources of varying proficiency. The combination of return-conditioning and longer context sequences enables the model to filter low-quality data while leveraging the increased dataset size.
However, several open questions remain regarding the optimal application of sequence modeling to robot imitation learning, particularly around reward function design and test-time error propagation.
Limitations
- • Training time: ~24 hours for mixed datasets (evaluation bottleneck)
- • Data imbalance: Heavily weighted toward low-quality MG trajectories
- • Error compounding: Test-time inaccuracies propagate through sequence
- • Task scope: Limited to low-dimensional robomimic manipulation tasks
- • Reward engineering: Required manual reward function tuning
Future Directions
- • Timestep encoding: Add counters to state embeddings for temporal awareness
- • Reward optimization: Automated reward shaping instead of manual tuning
- • Architecture search: Large-scale hyperparameter optimization
- • Complex tasks: Extension to Tool Hang, Square, long-horizon manipulation
- • Real-world deployment: Camera-based observations and physical robots
- • Self-improvement: Learn from agent's own previous policy versions
Conclusion
Decision Transformers can effectively learn from mixed-quality datasets, outperforming Behavioral Cloning via return conditioning and sequence modeling. By modeling multi-modal demonstrations with GMMs and benefiting from longer sequence contexts, this approach bridges the gap between RL theory and practical robot imitation learning.
This work demonstrates that return-conditioned sequence models are a promising direction for real-world robotics where data quality varies and online exploration is expensive or dangerous.
Contact & Collaboration
For questions about this research, collaboration opportunities, or implementation details, feel free to reach out: